Tacotron: End-to-end Speech Synthesis
2016 - present tags: google machine-learning sound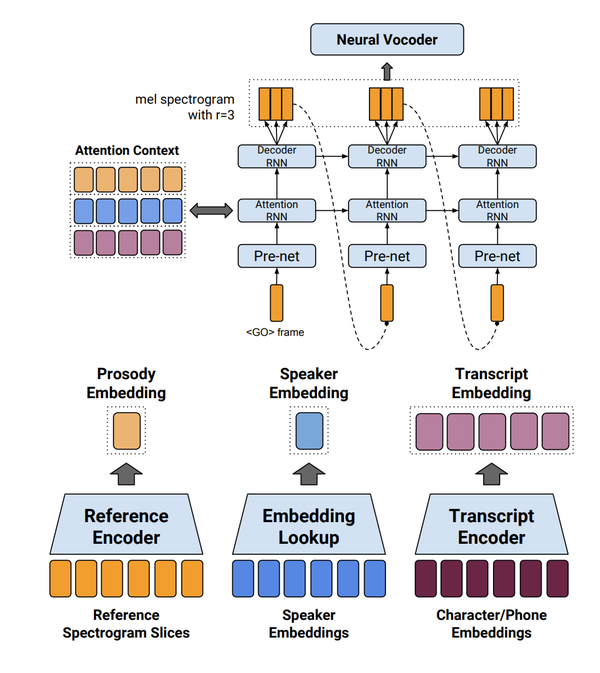
The most exciting work I’ve been involved with on the Sound Understanding team has been the development of Tacotron, an end-to-end speech synthesis system that produces speech “end-to-end” from characters to waveform. The initial system took verbalized characters as input and produced a log-magnitude mel spectrogram, which we then synthesize to waveform via standard signal processing methods (Griffin-Lim and an inverse Short-time Fourier Transform). In Tacotron 2, we replaced this hand-designed synthesis method with a neural vocoder, initially based on WaveNet.
One line of research on my team is direct-to-waveform acoustic models, skipping the intermediate spectrogram representation. In the Wave-Tacotron paper, we published a model that does just that.
Check out our publications page for the full list of research that my team has co-authored with the Google Brain, Deepmind, and Google Speech teams.